Starke Medien für starke Branchen
Der Österreichische Agrarverlag ist mit seiner Marke AV-Medien Herausgeber von 25 periodisch erscheinenden Special-Interest-Magazinen. Darüber hinaus informieren sich regelmäßig mehrere Millionen Leser auf insgesamt 18 einschlägigen Online-Fachportalen.
Unsere Themenschwerpunkte sind Landwirtschaft, Holz, Forst & Bau, Garten, Freizeit, Kulinarik & Lebensmittel sowie Immobilien, Handel und Bankenwesen.

Corporate Publishing
Entdecken Sie unsere Corporate Publishing Lösungen – wir bringen Ihr Unternehmen ins Gespräch! Wir bieten Ihnen journalistischen Content mit ansprechendem Design. Verleihen Sie Ihrer Marke Charakter und fördern Sie langfristigen Unternehmenserfolg durch regelmäßigen Austausch mit Ihrer Zielgruppe!

Unsere Medien
Verschaffen Sie sich einen Überblick über das breite Angebot an Print- und Onlinemedien, mit welchen wir jedes Jahr Millionen von Lesern aus unterschiedlichen Zielgruppen erreichen.

Unsere Werbelösungen
Wir passen unser Angebot an Ihre Marketingbedürfnisse an. Sie haben es in der Hand: Ob Print‑, Online‑, Social Media‑, klassische Newsletter-Werbung oder eine individuelle Kombination daraus. Wir beraten Sie gerne.
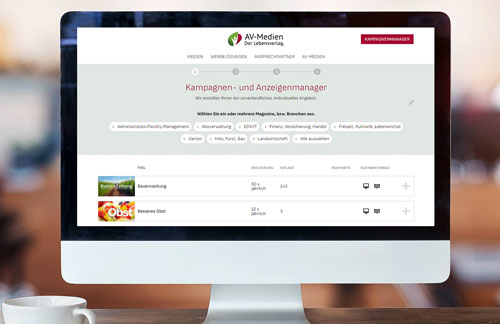
Kampagnenmanager
Mit dem Kampagnenmanager können Sie Ihre Kampagne selbst planen. Legen Sie fest, in welchen Branchen oder Medien Sie werben möchten. Der Kampagnenmanager zeigt Ihnen sofort, wie viele Leser-Touchpoints Sie erreichen können. Mit ein paar Klicks stellen Sie sich die perfekte Werbekampagne zusammen – angepasst an Ihre Zielgruppe und Bedürfnisse.
Planen Sie jetzt Ihren Auftritt in unseren Medien
HABEN WIR IHR INTERESSE GEWECKT?
Wir würden uns über Ihre Kontaktaufnahme sehr freuen. Hinterlassen Sie im Folgenden einfach Ihre Kontaktdaten und wir melden uns verlässlich zurück.